
땡글이LAB
[논문리뷰] e4e - Designing an Encoder for StyleGAN Image Manipulation 본문
이전에 리뷰했었던 pSp 논문과는 달리 본 논문은 이미지 조작(manipulation)에 적합한 인코딩을 수행하는 e4e 네트워크를 제안한다. 즉, pSp 에서 주장한 인코더는 input image를 잘 inversion 해주는 latent vector를 찾는 것이 목적이었다면 본 논문은 manipulation을 잘해주는 인코더를 제안한다는 점이 pSp 와의 차이점이라고 볼 수 있을 것 같다.
최적화 방식과 인코딩 방식 [Image Inversion]
최적화 방식과 인코더 방식의 차이점부터 다뤄보고자 한다. StyleGAN 혹은 StyleGANv2 에서 사용되는 최적화 방식은 input image x와 유사한 이미지를 얻기에 적합하지만, 조작(manipulation)에는 낮은 성능을 보인다.
하지만 인코더 방식은 input image x 와 유사도가 낮은 이미지를 생성하지만, 조작할 때에는 더욱 유리한 방식이다. 물론 최적화(optimization) 방식과 인코더 (encoder) 방식을 함께 사용한 하이브리드 (hybrid) 방식도 존재한다.
High-quality Inversion을 위해 필요한 조건 2가지
본 논문에서는 high quality inversion을 위하여 두 가지 조건이 만족되어야 한다고 주장한다.
- Editability
- Proper Reconstruction
- Distortion
- Perceptual quality
즉, 편집이 얼마나 잘 수행이 되는지(Editability)와 원본 이미지와 픽셀 수준에서 얼마나 유사한지(Distortion)과 원본 이미지와 지각적인 측면에서 얼마나 유사한지(Perceptual quality)에 대한 조건이 만족되어야 고품질의 inversion이 가능하다고 본 논문에서 주장한다.
본 논문의 동기(Motivation)
본 논문에서는 최대한 W 공간에 가까운 latent code를 생성하는 인코더 네트워크를 생성하는 것을 목표로 한다. 즉, W+ 영역에 W 에 가가운 영역으로 매핑하는 역할을 수행할 수 있다.
기존에 제안되었던 pSp 인코더 네트워크와 비교했을 때에는 Editing 성능이 매우 뛰어나다. 하지만 복원(reconstruction) 성능은 비교적 좋지 못하다.
아래의 Figure 1을 보면 알 수 있듯이, e4e 인코더를 사용했을 때의 editing 성능이 좋아졌음을 알 수 있다. StyleGAN 에서는 사람의 얼굴에 한정적으로 잘 동작하지만, 본 논문에서 주장하는 인코더는 사람의 얼굴 뿐만이 아니라, 다양한 도메인의 이미지에도 잘 동작함을 확인할 수 있다.

본 논문의 핵심 포인트(요약)
본 논문 저자들이 주장하는 본 논문의 핵심 포인트는 총 4가지이다.
- StyleGAN의 latent space를 분석하고 그 구조에 대해 새로운 관점을 제안한다.
- Distortion, Perception, Editability 사이의 tradeoff를 소개한다.
- 위의 tradeoff 를 특성화하고 인코더가 이를 제어하기 위해 두 가지 수단을 제안한다.
- 반전된 실제 이미지의 후속 편집을 허용하도록 특별히 설계된 새로운 인코더인 e4e 인코더를 제안한다.
본 논문과 관련된 연구들

Table 1을 보면 알 수 있듯이, W, Wk, W*, Wk* 등 많은 용어들이 나오는데, 이들의 정의는 다음과 같다.
- W : mapping network를 거친 뒤의 분포 (18개의 레이어가 모두 동일)
- Wk : mapping network를 거쳐서 뽑은 뒤에 레이어 단위로 cross-over할 때의 분포
- W* : 모든 레이어가 같은 값이 되도록 latent codes 를 최적화할 때의 분포 (기존의 w 최적화 방식)
- Wk* : 각 레이어가 개별적이도록 latent codes를 최적화할 때의 분포 (기존의 w+ 최적화 방식)

본 논문의 핵심 아이디어
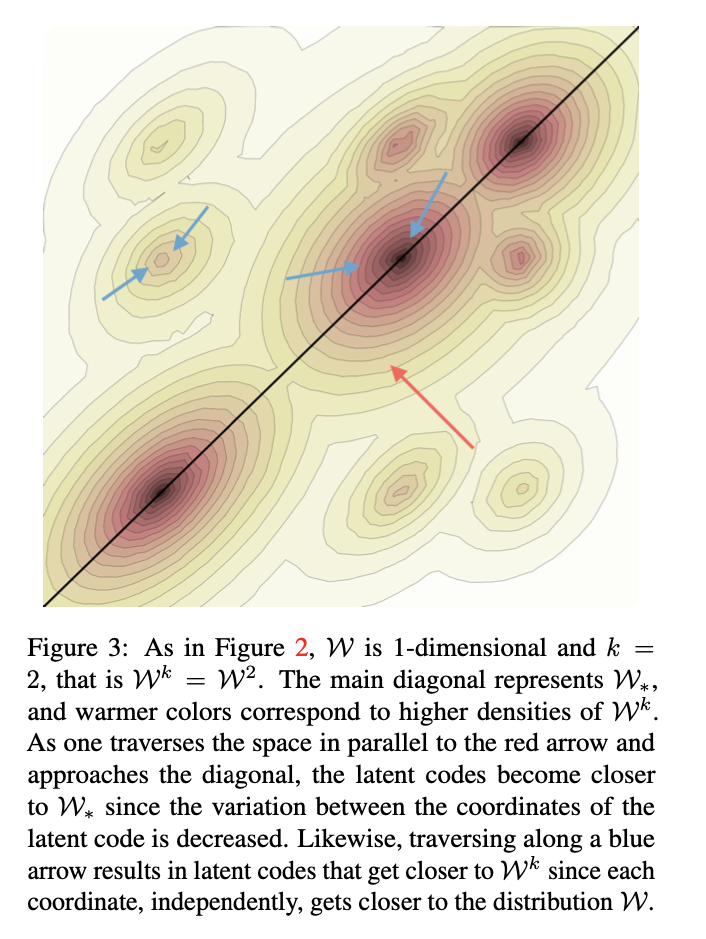
인코딩을 할 때에 최대한 W 분포를 지키도록 하는 것이다. 즉, 최대한 W 에 가까운 W+ 를 찾는 것이 본 논문의 목적이다. 이를 위해 본 논문에서는 두 가지 목표를 지키는 인코더를 제안한다.
- 각 style들이 low variance를 갖도록 한다.
- 빨간색 화살표 : 대각선(W* 분포)에 가까워지도록 함
- 각 style들이 개별적으로 W 분포를 따르도록 한다.
- 파란색 화살표 : Wk 분포에 가까워지도록 함
본 논문의 아키텍처
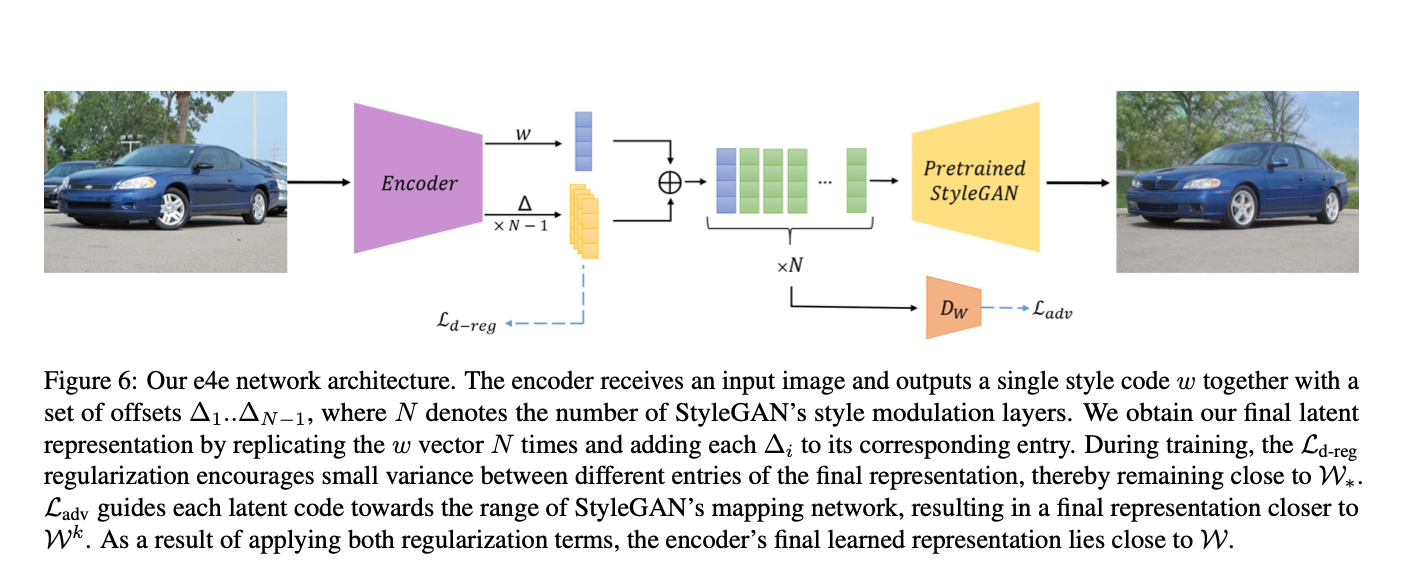
본 논문의 아키텍처는 다음과 같다. Encoder를 통해 latent space를 찾는다. 하지만 전통적인 인코더와는 다른 방식으로 offset 값을 추가적으로 요한다. 또한 각 레이어의 스타일들이 유사하도록 학습시킨다.
본 논문의 가장 큰 특징은 L(d-reg), L(adv)를 사용한다는 것이다. 두 개의 Loss function은 만들어지는 latent code가 W 분포에 가까워지도록 만들어주며 결과적으로 perceptual quality와 editability를 높일 수 있게 된다.
본 논문의 Loss function
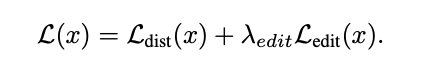
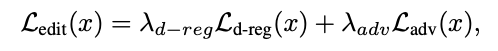
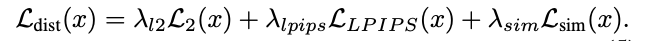
본 논문에서는 사용되는 Loss function은 다음과 같다.
본 논문의 결과

앞서 얘기했던 것처럼 최적화(optimization) 방식은 inversion에서는 좋은 성능을 보이지만 editing 에선 좋은 성능을 보이지 못한다. 하지만 Encoder 방식은 inversion에서는 원본 이미지와 차이가 있으나, editing에서 좋은 성능을 보이는 것을 알 수 있다.



